Building a RAG System from Text Documents with Milvus and Ollama
Who read documentaions for a software or instructions for a system anymore, right?! Retrieval-Augmented Generation, or RAG is one of the most practical applications of AI for working with large text collections. Instead of hoping a language model knows about your specific domain, RAG lets you feed it exactly the information it needs to give better answers.
The beauty of RAG lies in its simplicity. Rather than fine-tuning massive models or hoping your documents were in the training data, you create a searchable knowledge base from your texts and retrieve relevant pieces when someone asks a question. Think of it as giving your AI assistant a really good filing system and the ability to quickly find the right documents before answering.
Here, we’ll build a complete RAG system using Milvus as our vector database and Ollama for running language models locally. We’ll work through the entire process from a raw text, which is the documentaion for the Gmsh software to a web interface where users can ask questions and get contextual answers.
Understanding the RAG Architecture
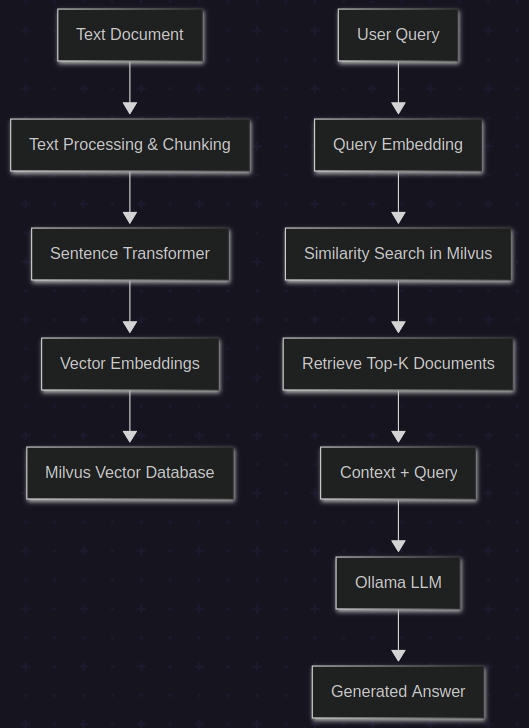
We will develop two main procedures: the indexing phase where we process documents and store them, and the retrieval phase where we answer questions.
Indexing
we take a text document and break it into meaningful chunks. These chunks get converted into vector embeddings using a sentence transformer model. These embeddings capture the semantic meaning of the text in a way that allows us to find similar content later. We store both the embeddings and the original text in Milvus, which serves as our vector database.
When someone asks a question, we convert their query into the same type of embedding, search for the most similar chunks in our database, and then feed both the question and the relevant context to a language model. The LLM generates an answer based on the retrieved information rather than just its training data.
Setting Up the Tools
We’ll need Milvus running as our vector database, Ollama with a language model for generation, and several Python libraries for text processing and embeddings. Milvus handles the heavy lifting of similarity search across high-dimensional vectors, while Ollama gives us local access to language models without sending data to external APIs.
For the embedding model, we’re using all-MiniLM-L6-v2 from Sentence Transformers. This model strikes a good balance between quality and speed, producing 384-dimensional vectors that capture semantic meaning effectively. It’s particularly good at understanding the relationships between different pieces of text, which is exactly what we need for retrieval.
Processing Documents into Searchable Chunks
The key to good RAG performance is how you chunk your documents. Too small and you lose context, too large and the retrieval becomes unfocused. I will try grouping 5 sentences together in this example, hoping that it provides enough context while keeping chunks focused on specific topics.
Here’s how we handle the document processing:
def create_vector_database(text, chunk_size=5):
model = SentenceTransformer('all-MiniLM-L6-v2')
# This will break text into sentences and group them
sentences = sent_tokenize(text)
text_chunks = [
' '.join(sentences[i:i + chunk_size])
for i in range(0, len(sentences), chunk_size)
]
# This converts chunks to embeddings
embeddings = model.encode(text_chunks)
embeddings_list = embeddings.tolist()
# This will store the data into a Milvus collection
connect_to_milvus()
collection = create_milvus_collection(MILVUS_COLLEC_NAME)
insert_vectors_to_milvus(collection, embeddings_list, text_chunks)
The sentence tokenization ensures we break text at natural boundaries, while the chunking strategy maintains coherent thoughts. Each chunk gets converted to a 384-dimensional vector that represents its semantic content.
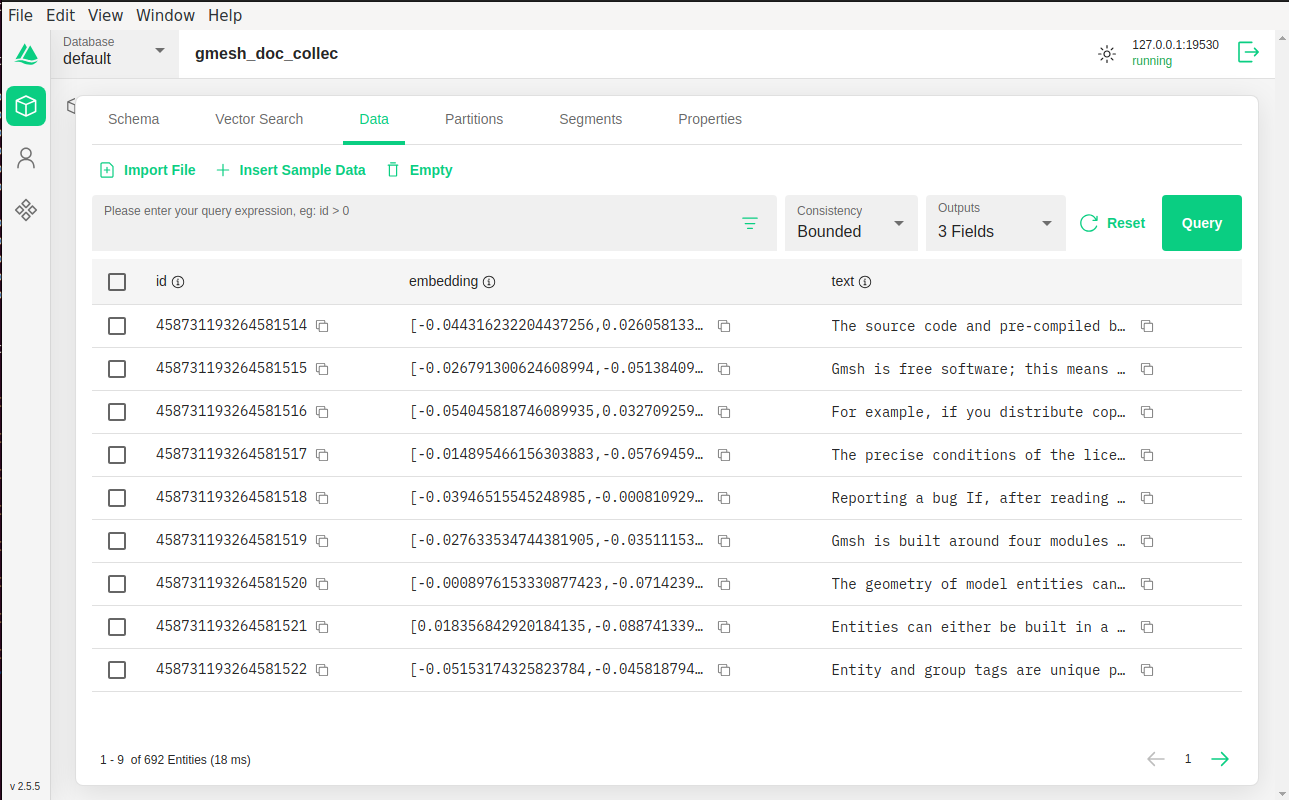
Building the Milvus Collection
To do this, I basically follow the same process that I discussed in a previous post. Milvus requires us to define a schema for our data before we can start storing vectors. Our schema is straightforward: we need an ID field for each record, the embedding vector itself, and the original text. The embedding field uses Milvus’s FLOAT_VECTOR type with 384 dimensions to match our sentence transformer output.
def create_milvus_collection(collection_name):
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=384),
FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=65535)
]
schema = CollectionSchema(fields, description="Vector database for documentation.")
collection = Collection(name=collection_name, schema=schema)
return collection
After creating the collection and inserting our data, we build an index to make searches fast. The IVF_FLAT index type works well for most use cases. We also load the collection into memory so searches happen quickly.
Implementing the Question-Answering Logic
The real magic happens during query time. When someone asks a question, we need to find the most relevant chunks from our database and use them to generate an answer. This involves converting the question to an embedding, searching for similar chunks, and then crafting a prompt that gives the language model both the question and the relevant context.
def retrieve_similar_documents(self, query, top_k=5):
# This will convert query into embedding usng the same model
query_embedding = self.model.encode([query]).tolist()
# Then, we search for similar chunks in the Milvus collection we created
results = self.collection.search(
data=query_embedding,
anns_field="embedding",
param={"metric_type": "L2", "params": {"nprobe": 10}},
limit=top_k,
output_fields=["text"]
)
# We then extract the tex and similarity scores
retrieved_docs = []
for hits in results:
for hit in hits:
retrieved_docs.append({
'text': hit.entity.get('text'),
'score': hit.score
})
return retrieved_docs
The similarity search uses L2 distance to find chunks whose embeddings are closest to the query embedding. Lower scores indicate higher similarity, and we focus on retrieving the top 5 matches to provide sufficient context without overwhelming the language model.
Crafting Effective Prompts
Once we have relevant chunks, we need to present them to the language model in a way that encourages accurate, contextual answers. The prompt structure is crucial here. We provide clear instructions, include all the retrieved context, and then ask the specific question.
def create_rag_prompt(self, query, retrieved_docs):
context = "\n\n".join([doc['text'] for doc in retrieved_docs])
prompt = f"""You are a helpful assistant that answers questions based on the provided context. Use the context below to answer the user's question. If the answer cannot be found in the context, say so clearly.
Context:
{context}
Question: {query}
Answer:"""
return prompt
This prompt structure helps the model understand its role and encourages it to stick to the provided context rather than hallucinating information. The clear separation between context and question makes it easy for the model to understand what information is available and what’s being asked.
Connecting to Ollama for Local Generation
Using Ollama for generation keeps everything local and gives us control over the model and its parameters. We send our crafted prompt to Ollama’s API and get back a generated response. The temperature and other parameters can be tuned based on whether you want more creative or more focused answers.
def query_ollama(self, prompt):
url = f"{OLLAMA_BASE_URL}/api/generate"
payload = {
"model": OLLAMA_MODEL,
"prompt": prompt,
"stream": False,
"options": {
"temperature": 0.7,
"top_p": 0.9,
"top_k": 40
}
}
response = requests.post(url, json=payload, timeout=120)
result = response.json()
return result.get('response', '')
The streaming option is set to false because we want to get the complete response at once for our web interface. In a production system, you might want to enable streaming for better user experience with longer answers.
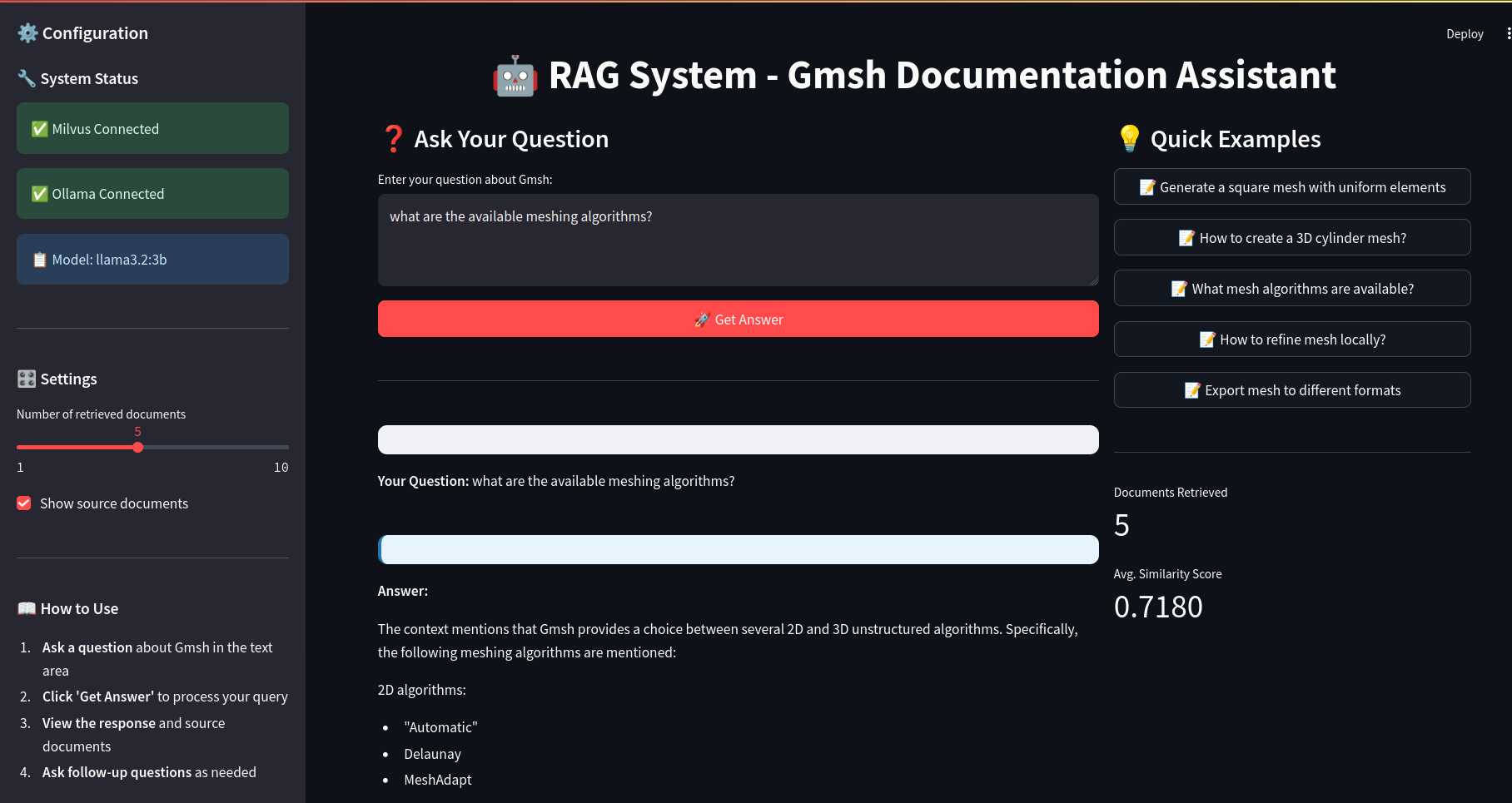
Building the Web Interface
The final piece is creating a user-friendly interface where people can ask questions and see both the answers and the source material. Streamlit makes this straightforward with its simple component model and built-in state management.
The interface shows system status to help users understand if everything is connected properly, provides a text area for questions, and displays both the generated answer and the source chunks that were used. This transparency is important because users can see where the information came from and judge the reliability of the answer.
def main():
st.title("RAG System - Documentation Assistant")
rag = initialize_rag()
milvus_status = rag.connect_to_milvus()
question = st.text_area("Enter your question:", height=100)
if st.button("Get Answer") and question.strip() and milvus_status:
with st.spinner("Searching for relevant information..."):
answer, retrieved_docs = rag.ask_question(question)
st.markdown(f"**Answer:** {answer}")
with st.expander("Source Documents"):
for i, doc in enumerate(retrieved_docs, 1):
st.markdown(f"**Source {i}** (Score: {doc['score']:.4f})")
st.text(doc['text'][:300] + "...")
The expandable source section lets users dive deeper into where the answer came from without cluttering the main interface. The similarity scores help users understand how confident the system is about the relevance of each source chunk.
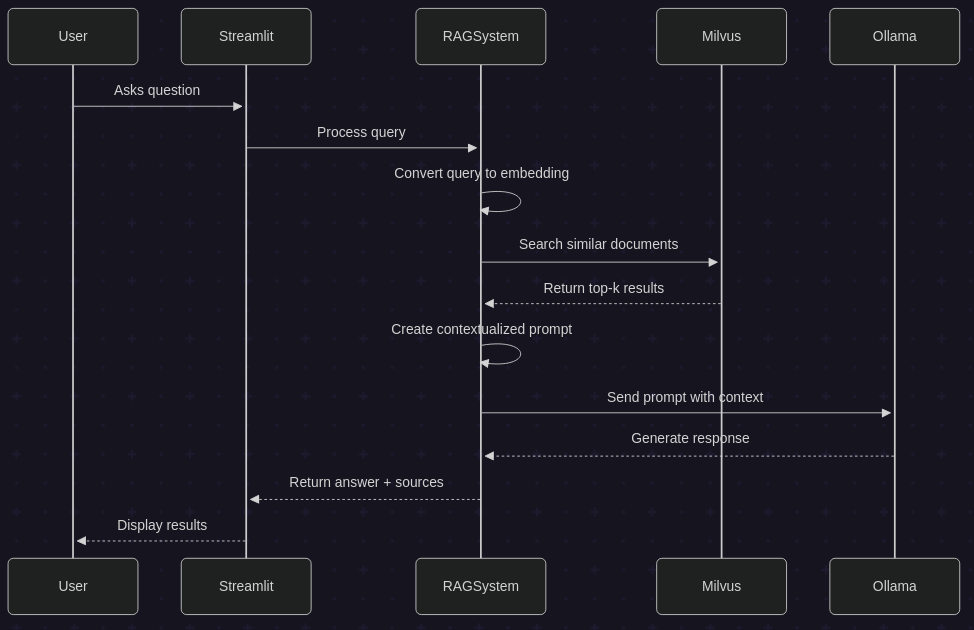
How It All Works Together
When someone asks a question through the web interface, the system follows a clear sequence. First, it converts the question into an embedding using the same sentence transformer model we used for indexing. Then it searches the Milvus database for chunks with similar embeddings. These chunks, along with the original question, get formatted into a prompt that’s sent to Ollama. The language model generates an answer based on the provided context, and the web interface displays both the answer and the source material.
This approach ensures that answers are grounded in your actual documents rather than the model’s training data. It’s particularly powerful for domain-specific knowledge where you need accurate, up-to-date information that might not be widely available.
Performance Considerations
The system is designed to be responsive for typical documentation sizes. Milvus handles the vector similarity search efficiently. The bottleneck is typically the language model generation, which depends on the model size and your hardware.
Caching the sentence transformer model in Streamlit prevents reloading on every query, and keeping the Milvus collection loaded in memory ensures fast searches. For larger document collections, you might need to consider more sophisticated indexing strategies or distributed setups.
The chunk size and retrieval parameters can be tuned based on your specific use case. Technical documentation might benefit from larger chunks to maintain context, while FAQ-style content might work better with smaller, more focused chunks.
Real-World Applications
This RAG system works well for many practical applications. Technical documentation, like the Gmsh documentation we used as an example, benefits from the system’s ability to find specific procedures and code examples. Internal company knowledge bases can be made searchable and accessible to employees without extensive training.
Research papers and academic literature can be processed to create specialized question-answering systems for specific fields. Legal documents, policy manuals, and regulatory texts all work well with this approach because accuracy and source attribution are crucial.
The local nature of the system using Ollama makes it suitable for sensitive or proprietary documents where you can’t send data to external APIs. Everything runs on your own infrastructure, giving you complete control over your data.
Whether you’re building a customer support tool, research assistant, or internal knowledge system, this RAG implementation gives you the core functionality needed to get started.
Complete code and setup instructions are available in the GitHub repository here.
Enjoy Reading This Article?
Here are some more articles you might like to read next: