Turning Text into a Vector Database with Milvus
In this tutorial, I am going to provide the steps required to convert a text into a vector database for easy searching and retrieval. The goal is to walk you through the process using a Python script that uses Milvus and Sentence Transformers. You can find the complete script in this GitHub repo.
What You Need
Before we get started, make sure you have the following:
- Milvus: You need a running instance of Milvus. Check out the Milvus installation guide if you haven’t set it up yet.
-
Python Packages: Install the required packages with this command:
pip install nltk sentence-transformers pymilvus - Your Text: Have a text file ready that you want to convert into a vector database. Just name it
text.txtand place it in adatafolder.
The Code
The script reads your text, processes it, and stores it in a Milvus collection. Here’s a quick overview of how it works:
- Read the Text: The script starts by reading the content of your
text.txtfile.def read_text_file(file_path): with open(file_path, 'r', encoding='utf-8') as file: return file.read() - Tokenization: It breaks the text into sentences and then chunks them into manageable pieces.
sentences = sent_tokenize(text) - Generate Embeddings: Using the
all-MiniLM-L6-v2model from Sentence Transformers, the script converts these text chunks into numerical embeddings.model = SentenceTransformer('all-MiniLM-L6-v2') text_chunks = [' '.join(sentences[i:i + chunk_size]) for i in range(0, len(sentences), chunk_size)] embeddings = model.encode(text_chunks) - Connect to Milvus: It establishes a connection to your Milvus instance.
def connect_to_milvus(): connections.connect("default", host="localhost", port="19530") - Create a Collection: A new collection is created in Milvus to store the embeddings and the original text.
connect_to_milvus() collection_name = MILVUS_COLLEC_NAME def create_milvus_collection(collection_name): fields = [ FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True), FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=384), FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=65535) ] schema = CollectionSchema(fields, description="Vector database for Common Sense.") collection = Collection(name=collection_name, schema=schema) return collection collection = create_milvus_collection(collection_name) - Insert Data: Finally, the embeddings and text are inserted into the collection, making them ready for efficient searching.
def insert_vectors_to_milvus(collection, embeddings_list, original_texts): logging.info(f"Number of embeddings: {len(embeddings_list)}") data = [ {"embedding": embedding, "text": original_text} for embedding, original_text in zip(embeddings_list, original_texts) ] try: collection.insert(data) logging.info(f"Inserted {len(embeddings_list)} vectors into Milvus.") except Exception as e: logging.error(f"Failed to insert data into Milvus: {e}") insert_vectors_to_milvus(collection, embeddings_list, text_chunks)
What’s Next?
After running the script, you’ll have a Milvus collection filled with your text data, ready for querying. You can now perform similarity searches and retrieve relevant information quickly and efficiently. Here is an example of how the output collection can look like in attu interface.
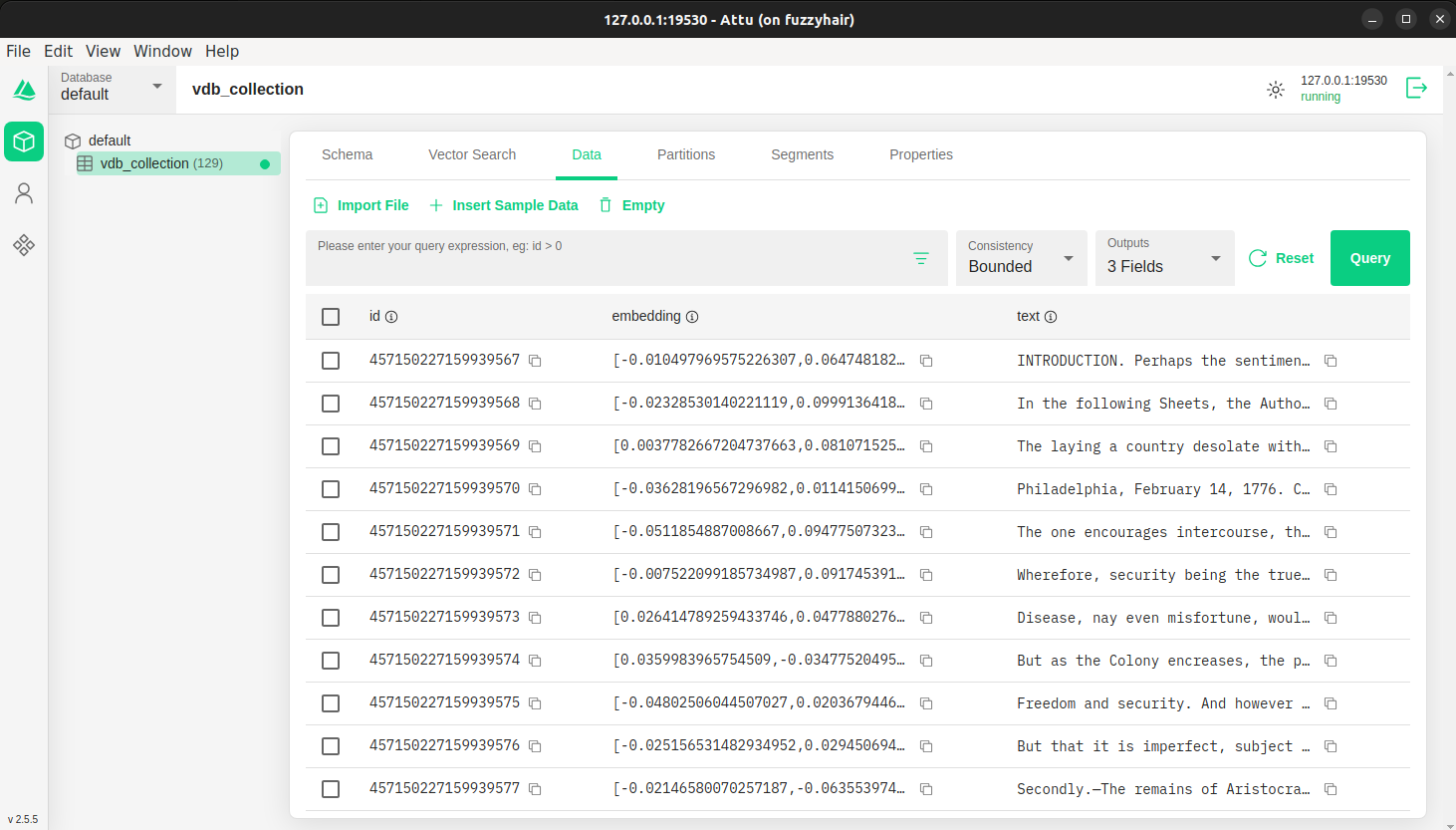
You have now successfully converted text into a vector database using Milvus. One exciting application of this approach is in Retrieval-Augmented Generation (RAG). By storing your text data in a vector database, you can enhance the capabilities of language models. When generating responses, the model can retrieve relevant information from the database, leading to more accurate and contextually relevant outputs. This is particularly useful in applications like chatbots, content generation, and question-answering systems.
Enjoy Reading This Article?
Here are some more articles you might like to read next: